[Serie: OpenNebula] [Arch] [Kvm] Overview e preparativi
Sun 02 February 2014Col 2014 ho intenzione di dedicarmi ad un progetto molto ambizioso : aprire un datacenter! :) Ovviamente non ho liquidità e fondi quindi ho deciso di cominciare il progetto Virtualizzando un ambiente OpenNebula via Kvm sul mio portatile Vaio #Arch Based.
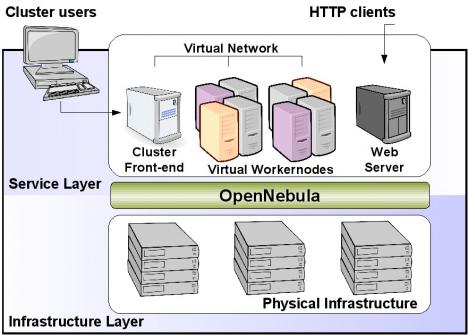
L'dea è di virtualizzare via Kvm delle macchine host L1 che formeranno il mio private "Cloud". Gli Host L1 saranno così configurati:
- 1/2 Host Storage (non ancora identificati) per la gestione storage degli altri host ed ovviamente dei filesystem dedicati alle VM L2/L3;
- 2/3 Host Centos 6.5 per la virtualizzazione che utilizzeranno libvirt, qemu-Kvm ed OpenvSwitch;
- 2 Host Centos 6.5 In HA per la gestione della Suite OpenNebula.
In questo Primo articolo parto dai presupposti, riportando le azioni per preparare il setup del mio Host Primario (Arch) per ospitare tutta la virtualizzazione sottostante. Questa prima parte della serie non è propriamente correlata ad OpenNebula ma è comunque importante ed ho piacere di condividerla nel caso qualche Archers passasse di qua ;). Per prima cosa do qualche info su pacchetti e tecnologia utilizzata:
1 ArchLinux Kernel 3.8.8-2-ARCH (<3.10): Non prendetemi per matto, aggiorno i componenti, ma esiste un bug di Kvm che previene l'utilizzo del Nesting Kvm a partire dal kernel 3.10 ed ho quindi dovuto downgradare il mio kernel ad una versione adeguata. 2 Filesystem Btrfs: Anche qua una nota dolente, dato che Btrfs è stupendo per moltissimi aspetti, ma non si può dire che sia performante quando si parla di gestire immagini dischi. Un modo per minimizzare i problemi di performance sono:
2 Disabilitare il Copy on Write nella directory che ospita i file dischi:
chattr -R +C ~/Path/To/VMs-Pool
3 Riempire le immagini preallocando metadati e spazio in modo da minimizzare la frammentazione:
qemu-img create -f qcow2 -o preallocation=metadata OpenNebula01 5G
ls -l OpenNebula01
-rw-r--r-- 1 j0lly j0lly 5369757696 31 dic 01.53 OpenNebula01
fallocate -l 5369757696 OpenNebula01
4 Libvirt config: Per poter produrre il laboratorio virtuale OpenNebula è necessario abilitare il nesting Kvm sull'Host principale, in modo da esporre VT ( o AMD-V ) nelle Cpu virtuali all'interno delle VM; il parametro nel Kernel per abilitare il nesting è kvm-intel.nested=1 e può essere caricato al boot via bootloader, via modprobe o, nel caso di Arch, più comodamente aggiungendo il file kvm_nesting.conf nella directory /etc/modprobe.d/ con il contenuto:
options kvm-intel nested=1
Un ulteriore accorgimento che consiglio è quello di gestire i pool su dischi/partizioni separate da /, ma in questo modo qemu, che viene startato come utente nobody, non sarà in grado di traversare le partizioni e non potrà accedere ai pool. Le opzioni sono varie ma io per comodità ho impostato il mio utente locale come owner del processo qemu, in modo da mantenere una configurazione funzionante senza dover utilizzare root per far girare le VM:
$~ grep -C2 j0lly /etc/libvirt/qemu.conf
# user = "100" # A user named "100" or a user with uid=100
#
user = "j0lly"
# The group for QEMU processes run by the system instance. It can b
Ultimo personale accorgimento è quello di aggiungere la variabile al .bashrc (o rc per la vostra shell) in modo da gestire automaticamente l'hypervisor con i vari tools e api di libvirt:
export LIBVIRT_DEFAULT_URI=qemu:///system
Tutte le configurazioni di base per Libvirt le potete invece trovare sul wiki di Arch che è sempre impeccabile. Con questo breve articolo ho spiegato cosa utilizzerò per l'installazione del Cloud virtuale che ospiterà il mio datacenter personale :). Nel Prossimo aritcolo mi occuperò dell'installazione di OpenNebula e della configurazione in HA tramite Red-Hat Cluster.
Stay Tuned!